Discrete mathematics[]
Set theory[]
- See also: *Naive set theory, *Zermelo–Fraenkel set theory, Set theory, *Set notation, *Set-builder notation, Set, *Algebra of sets, *Field of sets, and *Sigma-algebra
is the empty set (the additive identity)

is the universe of all elements (the multiplicative identity)

means that a is a element (or member) of set A. In other words a is in A.

- means the set of all x's that are members of the set A such that x is not a member of the real numbers. Could also be written


A set does not allow multiple instances of an element.

- A multiset does allow multiple instances of an element.

A set can contain other sets.

means that A is a proper subset of B

- means that a is a subset of itself. But a set is not a proper subset of itself.

is the Union of the sets A and B. In other words,



is the Intersection of the sets A and B. In other words, All a's in B.


- Associative:

- Distributive:

- Commutative:

is the Set difference of A and B. In other words,


- or is the complement of A.


or is the Anti-intersection of sets A and B which is the set of all objects that are a members of either A or B but not in both.



is the Cartesian product of A and B which is the set whose members are all possible ordered pairs (a, b) where a is a member of A and b is a member of B.

The Power set of a set A is the set whose members are all of the possible subsets of A.
A *cover of a set X is a collection of sets whose union contains X as a subset.[1]
A subset A of a topological space X is called *dense (in X) if every point x in X either belongs to A or is arbitrarily "close" to a member of A.
- A subset A of X is *meagre if it can be expressed as the union of countably many nowhere dense subsets of X.
*Disjoint union of sets = {1, 2, 3} and = {1, 2, 3} can be computed by finding:



so

Let H be the subgroup of the integers (mZ, +) = ({..., −2m, −m, 0, m, 2m, ...}, +) where m is a positive integer.
- Then the *cosets of H are the mZ + a = {..., −2m+a, −m+a, a, m+a, 2m+a, ...}.
- There are no more than m cosets, because mZ + m = m(Z + 1) = mZ.
- The coset (mZ + a, +) is the congruence class of a modulo m.[2]
- Cosets are not usually themselves subgroups of G, only subsets.
means "there exists at least one"

means "there exists one and only one"

means "for all"

means "and" (not to be confused with wedge product)

means "or" (not to be confused with antiwedge product)

Probability[]
is the cardinality of A which is the number of elements in A. See measure.

is the unconditional probability that A will happen.

is the conditional probability that A will happen given that B has happened.

means that the probability that A or B will happen is the probability of A plus the probability of B minus the probability that both A and B will happen.

means that the probability that A and B will happen is the probability of "A and B given B" times the probability of B.

is *Bayes' theorem

If you dont know the certainty then you can still know the probability. If you dont know the probability then you can always know the Bayesian probability. The Bayesian probability is the degree to which you expect something.
Even if you dont know anything about the system you can still know the *A priori Bayesian probability. As new information comes in the *Prior probability is updated and replaced with the *Posterior probability by using *Bayes' theorem.
From Wikipedia:Base rate fallacy:
In a city of 1 million inhabitants let there be 100 terrorists and 999,900 non-terrorists. In an attempt to catch the terrorists, the city installs an alarm system with a surveillance camera and automatic facial recognition software. 99% of the time it behaves correctly. 1% of the time it behaves incorrectly, ringing when it should not and failing to ring when it should. Suppose now that an inhabitant triggers the alarm. What is the chance that the person is a terrorist? In other words, what is P(T | B), the probability that a terrorist has been detected given the ringing of the bell? Someone making the 'base rate fallacy' would infer that there is a 99% chance that the detected person is a terrorist. But that is not even close. For every 1 million faces scanned it will see 100 terrorists and will correctly ring 99 times. But it will also ring falsely 9,999 times. So the true probability is only 99/(9,999+99) or about 1%.
permutation relates to the act of arranging all the members of a set into some sequence or *order.
The number of permutations of n distinct objects is n!.[3]
- A derangement is a permutation of the elements of a set, such that no element appears in its original position.
In other words, derangement is a permutation that has no *fixed points.
The number of *derangements of a set of size n, usually written *!n, is called the "derangement number" or "de Montmort number".[4]
- The *rencontres numbers are a triangular array of integers that enumerate permutations of the set { 1, ..., n } with specified numbers of fixed points: in other words, partial derangements.[5]
a combination is a selection of items from a collection, such that the order of selection does not matter.
For example, given three numbers, say 1, 2, and 3, there are three ways to choose two from this set of three: 12, 13, and 23.
More formally, a k-combination of a set S is a subset of k distinct elements of S.
If the set has n elements, the number of k-combinations is equal to the binomial coefficient
- Pronounced n choose k. The set of all k-combinations of a set S is often denoted by .


The central limit theorem (CLT) establishes that, in most situations, when *independent random variables are added, their properly normalized sum tends toward a normal distribution (informally a "bell curve") even if the original variables themselves are not normally distributed.[6]

A plot of normal distribution (or bell-shaped curve) where each band has a width of 1 standard deviation – See also: *68–95–99.7 rule
In statistics, the standard deviation (SD, also represented by the Greek letter sigma σ or the Latin letter s) is a measure that is used to quantify the amount of variation or *dispersion of a set of data values.[7]
A low standard deviation indicates that the data points tend to be close to the mean (also called the expected value) of the set, while a high standard deviation indicates that the data points are spread out over a wider range of values.[8]
The *hypergeometric distribution is a discrete probability distribution that describes the probability of k successes (random draws for which the object drawn has a specified feature) in n draws, without replacement, from a finite population of size N that contains exactly K objects with that feature, wherein each draw is either a success or a failure.
- In contrast, the *binomial distribution describes the probability of k successes in n draws with replacement.[9]
*Extreme value theory is used to model the risk of extreme, rare events, such as the 1755 Lisbon earthquake. It seeks to assess, from a given ordered sample of a given random variable, the probability of events that are more extreme than any previously observed.
See also *Dirichlet distribution, *Rice distribution, *Benford's law
Logic[]
From Wikipedia:Inductive reasoning
Given that "if A is true then the laws of cause and effect would cause B, C, and D to be true",
- An example of deduction would be
- "A is true therefore we can deduce that B, C, and D are true".
- An example of induction would be
- "B, C, and D are observed to be true therefore A might be true".
- A is a reasonable explanation for B, C, and D being true.
For example:
- A large enough asteroid impact would create a very large crater and cause a severe impact winter that could drive the dinosaurs to extinction.
- We observe that there is a very large crater in the Gulf of Mexico dating to very near the time of the extinction of the dinosaurs
- Therefore this impact is a reasonable explanation for the extinction of the dinosaurs.
The Temptation is to jump to the conclusion that this must therefore be the true explanation. But this is not necessarily the case. The Deccan Traps in India also coincide with the disappearance of the dinosaurs and could have been the cause their extinction.
A classical example of an incorrect inductive argument was presented by John Vickers:
- All of the swans we have seen are white.
- Therefore, we know that all swans are white.
The correct conclusion would be, "We expect that all swans are white". As a logic of induction, Bayesian inference does not determine which beliefs are a priori rational, but rather determines how we should rationally change the beliefs we have when presented with evidence. We begin by committing to a prior probability for a hypothesis based on logic or previous experience, and when faced with evidence, we adjust the strength of our belief (expectation) in that hypothesis in a precise manner using Bayesian logic.
Unlike deductive arguments, inductive reasoning allows for the possibility that the conclusion is false, even if all of the premises are true. Instead of being valid or invalid, inductive arguments are either strong or weak, which describes how probable it is that the conclusion is true.
It is often said that when thinking subjectively you will see whatever you want to see. In fact this is always the case. It's just that if you truly want to see what the facts say when they are allowed to speak for themselves then you will see that too. This is called "objectivity". It is man's capacity for objective reasoning that separates him from the animals. None of us are all-human though. All of us have a little bit of ego that tries to think subjectively. (Reality is not the egos native habitat.)
Morphisms[]
- See also: Higher category theory and *Multivalued function (misnomer)
| Injection | Invertible function Bijection |
Surjection |

|

|

|
Every function, f(x), has exactly one output for every input.
If its inverse function, f−1(x), has exactly one output for every input then the function is *invertible.

- If it isn't invertible then it doesn't have an inverse function.
An *involution which is a function that is its own inverse function. Example: f(x)=x/(x-1)

A morphism is exactly the same as a function but in Category theory every morphism has an inverse which is allowed to have more than one value or no value at all.
*Categories consist of:
- Objects (usually Sets)
- Morphisms (usually maps) possessing:
- one source object (domain)
- one target object (codomain)

a morphism is represented by an arrow:
- is written where x is in X and y is in Y.


- is written where y is in Y and z is in Z.


The *image of y is z.
The *preimage (or *fiber) of z is the set of all y whose image is z and is denoted
![{\displaystyle g^{-1}[z]}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/3493be2b009ed0016c847ac3ff58dfd4ae6ee245)
| A picture is worth 1000 words |
|
|

A space Y is a *covering space (a fiber bundle) of space Z if the map is locally homeomorphic.
- A covering space is a *universal covering space if it is *simply connected.
- The concept of a universal cover was first developed to define a natural domain for the *analytic continuation of an analytic function.
- The general theory of analytic continuation and its generalizations are known as *sheaf theory.
- The set of *germs can be considered to be the analytic continuation of an analytic function.
A topological space is *(path-)connected if no part of it is disconnected.

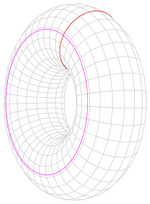
Not simply connected
A space is *simply connected if there are no holes passing all the way through it (therefore any loop can be shrunk to a point)
- See *Homology
Composition of morphisms:
- is written


- f is the *pullback of g
- f is the *lift of
- ? is the *pushforward of ?
A *homomorphism is a map from one set to another of the same type which preserves the operations of the algebraic structure:


- A *Functor is a homomorphism with a domain in one category and a codomain in another.
- A *group homomorphism from (G, ∗) to (H, ·) is a *function h : G → H such that
- for all u*v = c in G.

- For example

- Since log is a homomorphism that has an inverse that is also a homomorphism, log is an *isomorphism of groups. The logarithm is a *group isomorphism of the multiplicative group of *positive real numbers to the *additive group of real numbers, .


- See also *group action and *group orbit
A *Multicategory has morphisms with more than one source object.
A *Multilinear map :


has a corresponding Linear map::


Numerical methods[]
- See also: *Explicit and implicit methods
One of the simplest problems is the evaluation of a function at a given point.
The most straightforward approach, of just plugging in the number in the formula is sometimes not very efficient.
For polynomials, a better approach is using the *Horner scheme, since it reduces the necessary number of multiplications and additions.
Generally, it is important to estimate and control *round-off errors arising from the use of *floating point arithmetic.
*Interpolation solves the following problem: given the value of some unknown function at a number of points, what value does that function have at some other point between the given points?
*Extrapolation is very similar to interpolation, except that now we want to find the value of the unknown function at a point which is outside the given points.

*Regression is also similar, but it takes into account that the data is imprecise.
Given some points, and a measurement of the value of some function at these points (with an error), we want to determine the unknown function.
The *least squares-method is one popular way to achieve this.
Much effort has been put in the development of methods for solving *systems of linear equations.
- Standard direct methods, i.e., methods that use some *matrix decomposition
- *Gaussian elimination, *LU decomposition, *Cholesky decomposition for symmetric (or hermitian) and positive-definite matrix, and *QR decomposition for non-square matrices.
- *Jacobi method, *Gauss–Seidel method, *successive over-relaxation and *conjugate gradient method are usually preferred for large systems. General iterative methods can be developed using a *matrix splitting.
*Root-finding algorithms are used to solve nonlinear equations.
- If the function is differentiable and the derivative is known, then Newton's method is a popular choice.
- *Linearization is another technique for solving nonlinear equations.
Optimization problems ask for the point at which a given function is maximized (or minimized).
Often, the point also has to satisfy some *constraints.

Differential equation: If you set up 100 fans to blow air from one end of the room to the other and then you drop a feather into the wind, what happens?
The feather will follow the air currents, which may be very complex.
One approximation is to measure the speed at which the air is blowing near the feather every second, and advance the simulated feather as if it were moving in a straight line at that same speed for one second, before measuring the wind speed again.
This is called the *Euler method for solving an ordinary differential equation.
Information theory[]
From Wikipedia:Information theory:
Information theory studies the quantification, storage, and communication of information.
Communications over a channel—such as an ethernet cable—is the primary motivation of information theory.
From Wikipedia:Quantities of information:
Shannon derived a measure of information content called the *self-information or "surprisal" of a message m:

where is the probability that message m is chosen from all possible choices in the message space . The base of the logarithm only affects a scaling factor and, consequently, the units in which the measured information content is expressed. If the logarithm is base 2, the measure of information is expressed in units of *bits.


{kind=link}
{kind=link}
Information is transferred from a source to a recipient only if the recipient of the information did not already have the information to begin with. Messages that convey information that is certain to happen and already known by the recipient contain no real information. Infrequently occurring messages contain more information than more frequently occurring messages. This fact is reflected in the above equation - a certain message, i.e. of probability 1, has an information measure of zero. In addition, a compound message of two (or more) unrelated (or mutually independent) messages would have a quantity of information that is the sum of the measures of information of each message individually. That fact is also reflected in the above equation, supporting the validity of its derivation.
An example: The weather forecast broadcast is: "Tonight's forecast: Dark. Continued darkness until widely scattered light in the morning." This message contains almost no information. However, a forecast of a snowstorm would certainly contain information since such does not happen every evening. There would be an even greater amount of information in an accurate forecast of snow for a warm location, such as Miami. The amount of information in a forecast of snow for a location where it never snows (impossible event) is the highest (infinity).
The more surprising a message is the more information it conveys. The message "LLLLLLLLLLLLLLLLLLLLLLLLL" conveys exactly as much information as the message "25Ls". The first message which is 25 bytes long can therefore be "compressed" into the second message which is only 4 bytes long.
Early computers[]
- See also: *Time complexity
Tactical thinking[]
| Tactic X (Cooperate) |
Tactic Y (Defect) | |
|---|---|---|
| Tactic A (Cooperate) |
1, 1 | 5, -5 |
| Tactic B (Defect) |
-5, 5 | -5, -5 |
- See also *Wikipedia:Strategy (game theory)
- From Wikipedia:Game theory:
In the accompanying example there are two players; Player one (blue) chooses the row and player two (red) chooses the column.
Each player must choose without knowing what the other player has chosen.
The payoffs are provided in the interior.
The first number is the payoff received by Player 1; the second is the payoff for Player 2.
Tit for tat is a simple and highly effective tactic in game theory for the iterated prisoner's dilemma.
An agent using this tactic will first cooperate, then subsequently replicate an opponent's previous action.
If the opponent previously was cooperative, the agent is cooperative.
If not, the agent is not.[10]
| X | Y | |
|---|---|---|
| A | 1,-1 | -1,1 |
| B | -1,1 | 1,-1 |
In zero-sum games the sum of the payoffs is always zero (meaning that a player can only benefit at the expense of others).
Cooperation is impossible in a zero-sum game.
John Forbes Nash proved that there is a Nash equilibrium (an optimum tactic) for every finite game.
In the zero-sum game shown to the right the optimum tactic for player 1 is to randomly choose A or B with equal probability.
Strategic thinking differs from tactical thinking by taking into account how the short term goals and therefore optimum tactics change over time.
For example the opening, middlegame, and endgame of chess require radically different tactics.
See also: *Reverse game theory
Next section: Intermediate mathematics/Physics
Search Math wiki[]
See also[]
External links[]
- MIT open courseware
- Cheat sheets
- http://mathinsight.org
- https://math.stackexchange.com
- https://www.eng.famu.fsu.edu/~dommelen/quantum/style_a/IV._Supplementary_Informati.html
- http://www.sosmath.com
- https://webhome.phy.duke.edu/~rgb/Class/intro_math_review/intro_math_review/node1.html
- Wikiversity:Mathematics
- w:c:4chan-science:Mathematics
References[]
- ↑ Wikipedia:Cover (topology)
- ↑ Joshi p. 323
- ↑ Wikipedia:Permutation
- ↑ Wikipedia:derangement
- ↑ Wikipedia:rencontres numbers
- ↑ Wikipedia:Central limit theorem
- ↑ Bland, J.M.; Altman, D.G. (1996). "Statistics notes: measurement error". BMJ 312 (7047): 1654. doi:10.1136/bmj.312.7047.1654. PMC 2351401. PMID 8664723. //www.ncbi.nlm.nih.gov/pmc/articles/PMC2351401/.
- ↑ Wikipedia:standard deviation
- ↑ Wikipedia:Hypergeometric distribution
- ↑ Wikipedia:Tit for tat