Метод наименьших квадратов(МНК) - математический метод, по нахождению приближающей функции -
f
(
x
)
{\displaystyle f(x)}
по набору данных(точек)
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
…
,
(
x
n
,
y
n
)
}
{\displaystyle \{(x_{1},y_{1}),(x_{2},y_{2}),\ldots ,(x_{n},y_{n})\}}
Приближающая функция -
f
(
x
)
{\displaystyle f(x)}
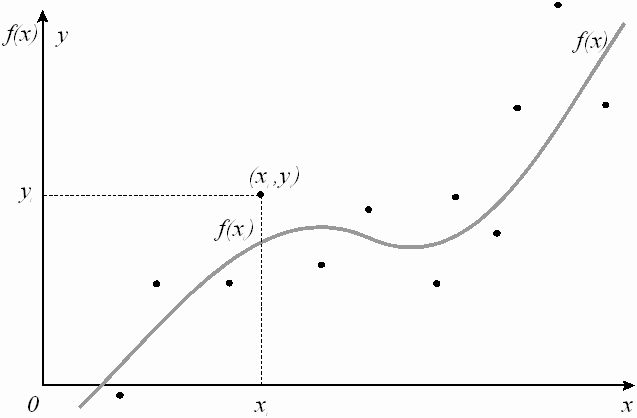
Сущность МНК [ ] Требуется по значениям
x
1
,
.
.
.
,
x
n
{\displaystyle x_1,...,x_n}
y
1
,
.
.
.
,
y
n
{\displaystyle y_{1},...,y_{n}}
f
(
x
)
{\displaystyle f(x)}
f
(
x
)
{\displaystyle f(x)}
(
x
i
,
y
i
)
{\displaystyle (x_i, y_i) }
Модели Регрессии
D
[
ε
]
=
1
n
∑
i
=
1
n
(
y
i
−
f
(
x
→
i
,
c
→
)
)
2
{\displaystyle D[{\boldsymbol {\varepsilon }}]={\frac {1}{n}}\sum _{i=1}^{n}(y_{i}-f({\vec {x}}_{i},{\vec {c}}))^{2}}
где
c
→
=
{
c
0
,
.
.
,
c
m
}
{\displaystyle {\vec {c}}=\{c_{0},..,c_{m}\}}
Далее будем рассматривать только случай однопараметрического (однофакторного) МНК, когда приближающая функция
f
(
x
→
i
,
c
→
)
{\displaystyle f({\vec {x}}_{i},{\vec {c}})}
x
{\displaystyle x}
D
[
ε
]
=
1
n
∑
i
=
1
n
(
y
i
−
f
(
x
i
,
c
→
)
)
2
{\displaystyle D[{\boldsymbol {\varepsilon }}]={\frac {1}{n}}\sum _{i=1}^{n}(y_{i}-f(x_{i},{\vec {c}}))^{2}}
Минимум
D
[
ε
]
{\displaystyle D[{\boldsymbol {\varepsilon }}]}
∂
D
[
ε
]
∂
c
→
=
0
{\displaystyle {\frac {\partial D[{\boldsymbol {\varepsilon }}]}{\partial {\vec {c}}}}=0}
∂
D
[
ε
]
∂
c
→
=
∂
D
[
ε
]
∂
c
0
e
→
0
+
…
+
∂
D
[
ε
]
∂
c
m
e
→
m
=
0
{\displaystyle {\frac {\partial D[{\boldsymbol {\varepsilon }}]}{\partial {\vec {c}}}}={\frac {\partial D[{\boldsymbol {\varepsilon }}]}{\partial c_{0}}}{\vec {e}}_{0}+\ldots +{\frac {\partial D[{\boldsymbol {\varepsilon }}]}{\partial c_{m}}}{\vec {e}}_{m}=0}
где
{
e
→
k
}
k
=
0
m
=
{
e
→
0
,
.
.
,
e
→
m
}
{\displaystyle \{{\vec {e}}_{k}\}_{k=0}^{m}=\{{\vec {e}}_{0},..,{\vec {e}}_{m}\}}
Минимизируя дисперсию ошибок
D
[
ε
]
{\displaystyle D[{\boldsymbol {\varepsilon }}]}
{
c
0
,
.
.
,
c
m
}
{\displaystyle \{c_{0},..,c_{m}\}}
{
e
→
k
}
k
=
0
m
=
{
φ
k
}
k
=
0
m
=
{
φ
0
(
x
)
,
.
.
,
φ
m
(
x
)
}
{\displaystyle \{{\vec {e}}_{k}\}_{k=0}^{m}=\{\varphi _{k}\}_{k=0}^{m}=\{\varphi _{0}(x),..,\varphi _{m}(x)\}}
m
<
n
{\displaystyle m < n}
f
(
x
,
c
→
)
=
∑
k
=
0
m
c
k
φ
k
(
x
)
{\displaystyle f(x,{\vec {c}})=\sum _{k=0}^{m}c_{k}\varphi _{k}(x)}
D
[
ε
]
=
1
n
∑
i
=
1
n
(
y
i
−
∑
k
=
0
m
c
k
φ
k
(
x
i
)
)
2
{\displaystyle D[{\boldsymbol {\varepsilon }}]={\frac {1}{n}}\sum _{i=1}^{n}(y_{i}-\sum _{k=0}^{m}c_{k}\varphi _{k}(x_{i}))^{2}}
Общий случай вычисления коэффициентов приближающей функции [ ] Для этого дифференцируем
D
[
ε
]
{\displaystyle D[{\boldsymbol {\varepsilon }}]}
D
[
ε
]
≡
D
{\displaystyle D[{\boldsymbol {\varepsilon }}]\equiv D}
c
j
{\displaystyle c_j}
{
c
k
}
k
=
0
m
{\displaystyle \{c_{k}\}_{k=0}^{m}}
j
{\displaystyle j}
0
{\displaystyle 0}
m
{\displaystyle m}
∂
D
∂
c
j
=
0
{\displaystyle {\frac {\partial D}{\partial c_{j}}}=0}
j
=
0..
m
{\displaystyle j=0..m}
систему уравнений относительно параметров
{
c
k
}
k
=
0
m
{\displaystyle \{c_{k}\}_{k=0}^{m}}
{
∂
D
∂
c
0
=
0
∂
D
∂
c
1
=
0
…
∂
D
∂
c
m
=
0
{\displaystyle {\begin{cases}{\frac {\partial D}{\partial c_{0}}}=0\\{\frac {\partial D}{\partial c_{1}}}=0\\\ldots \\{\frac {\partial D}{\partial c_{m}}}=0\end{cases}}}
∂
D
∂
c
j
=
∂
∂
c
j
∑
i
=
1
n
(
y
i
−
∑
k
=
0
m
c
k
φ
k
(
x
i
)
)
2
=
−
2
∑
i
=
1
n
(
y
i
−
∑
k
=
0
m
c
k
φ
k
(
x
i
)
)
∑
k
=
0
m
∂
c
k
∂
c
j
φ
k
(
x
i
)
=
0
{\displaystyle {\frac {\partial D}{\partial c_{j}}}={\frac {\partial }{\partial c_{j}}}\sum _{i=1}^{n}(y_{i}-\sum _{k=0}^{m}c_{k}\varphi _{k}(x_{i}))^{2}=-2\sum _{i=1}^{n}(y_{i}-\sum _{k=0}^{m}c_{k}\varphi _{k}(x_{i}))\sum _{k=0}^{m}{\frac {\partial c_{k}}{\partial c_{j}}}\varphi _{k}(x_{i})=0}
∂
c
k
∂
c
j
=
{
1
,
j
=
k
0
,
j
≠
k
≡
δ
j
k
{\displaystyle {\frac {\partial c_{k}}{\partial c_{j}}}={\begin{cases}1,j=k\\0,j\neq k\end{cases}}\equiv \delta _{jk}}
−
2
∑
i
=
1
n
(
y
i
−
∑
k
=
0
m
c
k
φ
k
(
x
i
)
)
∑
k
=
0
m
δ
j
k
φ
k
(
x
i
)
=
0
{\displaystyle -2\sum _{i=1}^{n}(y_{i}-\sum _{k=0}^{m}c_{k}\varphi _{k}(x_{i}))\sum _{k=0}^{m}\delta _{jk}\varphi _{k}(x_{i})=0}
Используя:
∑
k
=
0
m
δ
j
k
φ
k
(
x
)
=
φ
j
(
x
)
{\displaystyle \sum _{k=0}^{m}\delta _{jk}\varphi _{k}(x)=\varphi _{j}(x)}
приходим к:
∑
i
=
1
n
[
y
i
−
∑
k
=
0
m
c
k
φ
k
(
x
i
)
]
φ
j
(
x
i
)
=
0
{\displaystyle \sum _{i=1}^{n}[y_{i}-\sum _{k=0}^{m}c_{k}\varphi _{k}(x_{i})]\varphi _{j}(x_{i})=0}
j
=
0
…
m
{\displaystyle j=0\ldots m}
Распишем предыдущую формулу в виде системы
m
+
1
{\displaystyle m+1}
{
∑
i
=
1
n
[
y
i
−
∑
k
=
0
m
c
k
φ
k
(
x
i
)
]
φ
0
(
x
i
)
=
0
∑
i
=
1
n
[
y
i
−
∑
k
=
0
m
c
k
φ
k
(
x
i
)
]
φ
1
(
x
i
)
=
0
…
∑
i
=
1
n
[
y
i
−
∑
k
=
0
m
c
k
φ
k
(
x
i
)
]
φ
m
(
x
i
)
=
0
{\displaystyle {\begin{cases}\sum _{i=1}^{n}[y_{i}-\sum _{k=0}^{m}c_{k}\varphi _{k}(x_{i})]\varphi _{0}(x_{i})=0\\\sum _{i=1}^{n}[y_{i}-\sum _{k=0}^{m}c_{k}\varphi _{k}(x_{i})]\varphi _{1}(x_{i})=0\\\dots \\\sum _{i=1}^{n}[y_{i}-\sum _{k=0}^{m}c_{k}\varphi _{k}(x_{i})]\varphi _{m}(x_{i})=0\\\end{cases}}}
Процесс приведения системы уравнений к матричному виду:
Раскроем скобки и перенесём
y
i
φ
0
(
x
i
)
{\displaystyle y_{i}\varphi _{0}(x_{i})}
{
∑
i
=
1
n
φ
0
(
x
i
)
∑
k
=
0
m
c
k
φ
k
(
x
i
)
=
∑
i
=
1
n
y
i
φ
0
(
x
i
)
∑
i
=
1
n
φ
1
(
x
i
)
∑
k
=
0
m
c
k
φ
k
(
x
i
)
=
∑
i
=
1
n
y
i
φ
1
(
x
i
)
…
∑
i
=
1
n
φ
m
(
x
i
)
∑
k
=
0
m
c
k
φ
k
(
x
i
)
=
∑
i
=
1
n
y
i
φ
m
(
x
i
)
{\displaystyle {\begin{cases}\sum _{i=1}^{n}\varphi _{0}(x_{i})\sum _{k=0}^{m}c_{k}\varphi _{k}(x_{i})=\sum _{i=1}^{n}y_{i}\varphi _{0}(x_{i})\\\sum _{i=1}^{n}\varphi _{1}(x_{i})\sum _{k=0}^{m}c_{k}\varphi _{k}(x_{i})=\sum _{i=1}^{n}y_{i}\varphi _{1}(x_{i})\\\dots \\\sum _{i=1}^{n}\varphi _{m}(x_{i})\sum _{k=0}^{m}c_{k}\varphi _{k}(x_{i})=\sum _{i=1}^{n}y_{i}\varphi _{m}(x_{i})\\\end{cases}}}
В левой части, раскроем сумму по
k
{\displaystyle k}
{
∑
i
=
1
n
[
c
0
φ
0
2
(
x
i
)
+
c
1
φ
0
(
x
i
)
φ
1
(
x
i
)
+
.
.
.
+
c
m
φ
0
(
x
i
)
φ
m
(
x
i
)
]
=
∑
i
=
1
n
y
i
φ
0
(
x
i
)
∑
i
=
1
n
[
c
0
φ
1
(
x
i
)
φ
0
(
x
i
)
+
c
1
φ
1
2
(
x
i
)
+
.
.
.
+
c
m
φ
1
(
x
i
)
φ
m
(
x
i
)
]
=
∑
i
=
1
n
y
i
φ
1
(
x
i
)
…
∑
i
=
1
n
[
c
0
φ
m
(
x
i
)
φ
0
(
x
i
)
+
c
1
φ
m
(
x
i
)
φ
1
(
x
i
)
+
.
.
.
+
c
m
φ
m
2
(
x
i
)
]
=
∑
i
=
1
n
y
i
φ
m
(
x
i
)
{\displaystyle {\begin{cases}\sum _{i=1}^{n}[c_{0}\varphi _{0}^{2}(x_{i})+c_{1}\varphi _{0}(x_{i})\varphi _{1}(x_{i})+...+c_{m}\varphi _{0}(x_{i})\varphi _{m}(x_{i})]=\sum _{i=1}^{n}y_{i}\varphi _{0}(x_{i})\\\sum _{i=1}^{n}[c_{0}\varphi _{1}(x_{i})\varphi _{0}(x_{i})+c_{1}\varphi _{1}^{2}(x_{i})+...+c_{m}\varphi _{1}(x_{i})\varphi _{m}(x_{i})]=\sum _{i=1}^{n}y_{i}\varphi _{1}(x_{i})\\\dots \\\sum _{i=1}^{n}[c_{0}\varphi _{m}(x_{i})\varphi _{0}(x_{i})+c_{1}\varphi _{m}(x_{i})\varphi _{1}(x_{i})+...+c_{m}\varphi _{m}^{2}(x_{i})]=\sum _{i=1}^{n}y_{i}\varphi _{m}(x_{i})\\\end{cases}}}
Используя следующие переобозначения:
⟨
φ
j
,
φ
k
⟩
=
∑
i
=
1
n
φ
j
(
x
i
)
φ
k
(
x
i
)
{\displaystyle \langle \varphi _{j},\varphi _{k}\rangle =\sum _{i=1}^{n}\varphi _{j}(x_{i})\varphi _{k}(x_{i})}
⟨
y
,
φ
j
⟩
=
∑
i
=
1
n
y
i
φ
j
(
x
i
)
{\displaystyle \langle y,\varphi _{j}\rangle =\sum _{i=1}^{n}y_{i}\varphi _{j}(x_{i})}
Запишем предыдущую систему уравнений в матричном виде:
A
c
→
=
b
→
{\displaystyle A{\vec {c}}={\vec {b}}}
где
A
=
(
⟨
φ
0
,
φ
0
⟩
⟨
φ
1
,
φ
0
⟩
⋯
⟨
φ
m
,
φ
0
⟩
⟨
φ
0
,
φ
1
⟩
⟨
φ
1
,
φ
1
⟩
⋯
⟨
φ
m
,
φ
1
⟩
⋮
⋮
⋱
⋮
⟨
φ
0
,
φ
m
⟩
⟨
φ
1
,
φ
m
⟩
⋯
⟨
φ
m
,
φ
m
⟩
)
{\displaystyle A={\begin{pmatrix}\langle \varphi _{0},\varphi _{0}\rangle &\langle \varphi _{1},\varphi _{0}\rangle &\cdots &\langle \varphi _{m},\varphi _{0}\rangle \\\langle \varphi _{0},\varphi _{1}\rangle &\langle \varphi _{1},\varphi _{1}\rangle &\cdots &\langle \varphi _{m},\varphi _{1}\rangle \\\vdots &\vdots &\ddots &\vdots \\\langle \varphi _{0},\varphi _{m}\rangle &\langle \varphi _{1},\varphi _{m}\rangle &\cdots &\langle \varphi _{m},\varphi _{m}\rangle \\\end{pmatrix}}}
c
→
=
(
c
0
c
1
⋮
c
m
)
{\displaystyle {\vec {c}}={\begin{pmatrix}c_{0}\\c_{1}\\\vdots \\c_{m}\end{pmatrix}}}
b
→
=
(
⟨
y
,
φ
0
⟩
⟨
y
,
φ
1
⟩
⋮
⟨
y
,
φ
m
⟩
)
{\displaystyle {\vec {b}}={\begin{pmatrix}\langle y,\varphi _{0}\rangle \\\langle y,\varphi _{1}\rangle \\\vdots \\\langle y,\varphi _{m}\rangle \\\end{pmatrix}}}
Матрица
A
{\displaystyle A}
матрицей Грама .
решаем систему матричным методом и находим вектор искомых коэффициентов приближающей функции:
c
→
=
{
c
0
,
c
1
,
…
,
c
m
}
{\displaystyle {\vec {c}}=\{c_{0}\;,c_{1},\;\ldots ,\;c_{m}\;\}}
c
→
=
(
c
0
c
1
⋮
c
m
)
=
A
−
1
b
=
(
⟨
φ
0
,
φ
0
⟩
⟨
φ
1
,
φ
0
⟩
⋯
⟨
φ
m
,
φ
0
⟩
⟨
φ
0
,
φ
1
⟩
⟨
φ
1
,
φ
1
⟩
⋯
⟨
φ
m
,
φ
1
⟩
⋮
⋮
⋱
⋮
⟨
φ
0
,
φ
m
⟩
⟨
φ
1
,
φ
m
⟩
⋯
⟨
φ
m
,
φ
m
⟩
)
−
1
(
⟨
y
,
φ
0
⟩
⟨
y
,
φ
1
⟩
⋮
⟨
y
,
φ
m
⟩
)
{\displaystyle {\vec {c}}={\begin{pmatrix}c_{0}\\c_{1}\\\vdots \\c_{m}\end{pmatrix}}=A^{-1}b={\begin{pmatrix}\langle \varphi _{0},\varphi _{0}\rangle &\langle \varphi _{1},\varphi _{0}\rangle &\cdots &\langle \varphi _{m},\varphi _{0}\rangle \\\langle \varphi _{0},\varphi _{1}\rangle &\langle \varphi _{1},\varphi _{1}\rangle &\cdots &\langle \varphi _{m},\varphi _{1}\rangle \\\vdots &\vdots &\ddots &\vdots \\\langle \varphi _{0},\varphi _{m}\rangle &\langle \varphi _{1},\varphi _{m}\rangle &\cdots &\langle \varphi _{m},\varphi _{m}\rangle \\\end{pmatrix}}^{-1}{\begin{pmatrix}\langle y,\varphi _{0}\rangle \\\langle y,\varphi _{1}\rangle \\\vdots \\\langle y,\varphi _{m}\rangle \\\end{pmatrix}}}
В результате, мы нашли приближающую функцию
f
(
x
)
{\displaystyle f(x)}
f
(
x
)
=
(
c
0
c
1
⋮
c
m
)
(
φ
0
(
x
)
,
φ
1
(
x
)
,
…
,
φ
m
(
x
)
)
=
c
0
φ
0
(
x
)
+
c
1
φ
1
(
x
)
+
.
.
.
+
c
m
φ
m
(
x
)
{\displaystyle f(x)={\begin{pmatrix}c_{0}\\c_{1}\\\vdots \\c_{m}\end{pmatrix}}{\begin{pmatrix}\varphi _{0}(x),&\varphi _{1}(x),&\ldots ,&\varphi _{m}(x)\end{pmatrix}}=c_{0}\varphi _{0}(x)+c_{1}\varphi _{1}(x)+...+c_{m}\varphi _{m}(x)}
Основные случаи [ ] Степенное разложение (общий случай)[ ] Часто в виде системы линейно-независимых функций
{
φ
k
(
x
)
}
k
=
0
m
{\displaystyle \{\varphi _{k}(x)\}_{k=0}^{m}}
{
1
,
x
,
.
.
,
x
m
}
{\displaystyle \{1,x,..,x^{m}\}}
f
(
x
,
c
→
)
=
c
0
+
c
1
x
+
c
2
x
2
+
.
.
.
+
c
m
x
m
=
∑
k
=
0
m
c
k
x
k
{\displaystyle f(x,{\vec {c}})=c_{0}+c_{1}x+c_{2}x^{2}+...+c_{m}x^{m}=\sum _{k=0}^{m}c_{k}x^{k}}
Тогда система уравнений
A
c
→
=
b
→
{\displaystyle A{\vec {c}}={\vec {b}}}
(далее производится суммирование
∑
i
=
1
n
{\displaystyle \sum_{i=1}^n}
∑
{\displaystyle \sum}
где
A
=
{\displaystyle A=}
(
∑
1
∑
x
i
⋯
∑
x
i
m
∑
x
i
∑
x
i
2
⋯
∑
x
i
m
+
1
⋮
⋮
⋱
⋮
∑
x
i
m
∑
x
i
m
+
1
⋯
∑
x
i
2
m
)
{\displaystyle {\begin{pmatrix}\sum 1&\sum x_{i}&\cdots &\sum x_{i}^{m}\\\sum x_{i}&\sum x_{i}^{2}&\cdots &\sum x_{i}^{m+1}\\\vdots &\vdots &\ddots &\vdots \\\sum x_{i}^{m}&\sum x_{i}^{m+1}&\cdots &\sum x_{i}^{2m}\end{pmatrix}}}
b
=
(
∑
y
i
∑
y
i
x
i
⋮
∑
y
i
x
i
m
)
{\displaystyle b={\begin{pmatrix}\sum y_{i}\\\sum y_{i}x_{i}\\\vdots \\\sum y_{i}x_{i}^{m}\end{pmatrix}}}
Вектор коэффициентов:
c
→
=
(
c
0
c
1
⋮
c
m
)
=
A
−
1
b
=
(
∑
1
∑
x
i
⋯
∑
x
i
m
∑
x
i
∑
x
i
2
⋯
∑
x
i
m
+
1
⋮
⋮
⋱
⋮
∑
x
i
m
∑
x
i
m
+
1
⋯
∑
x
i
2
m
)
−
1
(
∑
y
i
∑
y
i
x
i
⋮
∑
y
i
x
i
m
)
{\displaystyle {\vec {c}}={\begin{pmatrix}c_{0}\\c_{1}\\\vdots \\c_{m}\end{pmatrix}}=A^{-1}b={\begin{pmatrix}\sum 1&\sum x_{i}&\cdots &\sum x_{i}^{m}\\\sum x_{i}&\sum x_{i}^{2}&\cdots &\sum x_{i}^{m+1}\\\vdots &\vdots &\ddots &\vdots \\\sum x_{i}^{m}&\sum x_{i}^{m+1}&\cdots &\sum x_{i}^{2m}\end{pmatrix}}^{-1}{\begin{pmatrix}\sum y_{i}\\\sum y_{i}x_{i}\\\vdots \\\sum y_{i}x_{i}^{m}\end{pmatrix}}}
f
(
x
)
=
(
c
0
c
1
⋮
c
m
)
{
1
,
x
,
…
,
x
m
}
=
c
0
+
c
1
x
+
c
2
x
2
+
.
.
.
+
c
m
x
m
{\displaystyle f(x)={\begin{pmatrix}c_{0}\\c_{1}\\\vdots \\c_{m}\end{pmatrix}}\{1,x,\ldots ,x^{m}\}=c_{0}+c_{1}x+c_{2}x^{2}+...+c_{m}x^{m}}
На практике применима до степени
m
≤
5
{\displaystyle m\leq 5}
A
−
1
{\displaystyle A^{-1}}
Приближение линейной зависимостью [ ] Набор данных(точки)
{
x
i
,
y
i
}
i
=
1
n
{\displaystyle \{x_{i},y_{i}\}_{i=1}^{n}}
f
(
x
)
=
c
0
+
c
1
x
{\displaystyle f(x)=c_{0}+c_{1}x}
Базисные функции линейной зависимости:
φ
0
(
x
)
=
1
,
φ
1
(
x
)
=
x
{\displaystyle \varphi _{0}(x)=1,\ \varphi _{1}(x)=x}
(далее производится суммирование
∑
i
=
1
n
{\displaystyle \sum_{i=1}^n}
A
=
(
⟨
φ
0
,
φ
0
⟩
⟨
φ
1
,
φ
0
⟩
⟨
φ
0
,
φ
1
⟩
⟨
φ
1
,
φ
1
⟩
)
=
(
∑
1
∑
x
i
∑
x
i
∑
x
i
2
)
{\displaystyle A={\begin{pmatrix}\langle \varphi _{0},\varphi _{0}\rangle &\langle \varphi _{1},\varphi _{0}\rangle \\\langle \varphi _{0},\varphi _{1}\rangle &\langle \varphi _{1},\varphi _{1}\rangle \\\end{pmatrix}}={\begin{pmatrix}\sum 1&\sum x_{i}\\\sum x_{i}&\sum x_{i}^{2}\\\end{pmatrix}}}
b
=
(
⟨
y
,
φ
0
⟩
⟨
y
,
φ
1
⟩
)
=
(
∑
y
i
∑
y
i
x
i
)
{\displaystyle b={\begin{pmatrix}\langle y,\varphi _{0}\rangle \\\langle y,\varphi _{1}\rangle \end{pmatrix}}={\begin{pmatrix}\sum y_{i}\\\sum y_{i}x_{i}\end{pmatrix}}}
∑
i
=
1
n
1
=
n
{\displaystyle \sum _{i=1}^{n}1=n}
c
→
=
A
−
1
b
→
=
(
n
∑
x
i
∑
x
i
∑
x
i
2
)
−
1
⋅
(
∑
y
i
∑
y
i
x
i
)
{\displaystyle {\vec {c}}=A^{-1}{\vec {b}}={\begin{pmatrix}n&\sum x_{i}\\\sum x_{i}&\sum x_{i}^{2}\\\end{pmatrix}}^{-1}\cdot {\begin{pmatrix}\sum y_{i}\\\sum y_{i}x_{i}\end{pmatrix}}}
A
−
1
=
1
n
∑
x
i
2
−
(
∑
x
i
)
2
(
∑
x
i
2
−
∑
x
i
−
∑
x
i
n
)
{\displaystyle A^{-1}={\frac {1}{n\sum x_{i}^{2}-(\sum x_{i})^{2}}}{\begin{pmatrix}\sum x_{i}^{2}&-\sum x_{i}\\-\sum x_{i}&n\\\end{pmatrix}}}
c
→
=
(
c
0
c
1
)
=
A
−
1
b
→
=
1
n
∑
x
i
2
−
(
∑
x
i
)
2
(
∑
x
i
2
−
∑
x
i
−
∑
x
i
n
)
⋅
(
∑
y
i
∑
y
i
x
i
)
{\displaystyle {\vec {c}}={\begin{pmatrix}c_{0}\\c_{1}\end{pmatrix}}=A^{-1}{\vec {b}}={\frac {1}{n\sum x_{i}^{2}-(\sum x_{i})^{2}}}{\begin{pmatrix}\sum x_{i}^{2}&-\sum x_{i}\\-\sum x_{i}&n\\\end{pmatrix}}\cdot {\begin{pmatrix}\sum y_{i}\\\sum y_{i}x_{i}\end{pmatrix}}}
c
→
=
(
c
0
c
1
)
=
1
n
∑
x
i
2
−
(
∑
x
i
)
2
(
∑
x
i
2
∑
y
i
−
∑
x
i
∑
y
i
x
i
n
∑
y
i
x
i
−
∑
x
i
∑
y
i
)
{\displaystyle {\vec {c}}={\begin{pmatrix}c_{0}\\c_{1}\end{pmatrix}}={\frac {1}{n\sum x_{i}^{2}-(\sum x_{i})^{2}}}{\begin{pmatrix}\sum x_{i}^{2}\sum y_{i}-\sum x_{i}\sum y_{i}x_{i}\\n\sum y_{i}x_{i}-\sum x_{i}\sum y_{i}\end{pmatrix}}}
Таким образом вычислили коэффициенты и нашли приближающую функцию:
c
0
=
∑
x
i
2
∑
y
i
−
∑
x
i
∑
y
i
x
i
n
∑
x
i
2
−
(
∑
x
i
)
2
{\displaystyle c_{0}={\frac {\sum x_{i}^{2}\sum y_{i}-\sum x_{i}\sum y_{i}x_{i}}{n\sum x_{i}^{2}-(\sum x_{i})^{2}}}}
c
1
=
n
∑
y
i
x
i
−
∑
x
i
∑
y
i
n
∑
x
i
2
−
(
∑
x
i
)
2
{\displaystyle c_{1}={\frac {n\sum y_{i}x_{i}-\sum x_{i}\sum y_{i}}{n\sum x_{i}^{2}-(\sum x_{i})^{2}}}}
f
(
x
)
=
c
0
+
c
1
x
{\displaystyle f(x)=c_{0}+c_{1}x}
Ортогональность линейно-независимой системы функций [ ] Чтобы упростить решение системы уравнений
A
c
→
=
b
→
{\displaystyle A{\vec {c}}={\vec {b}}}
c
→
{\displaystyle \vec{c}}
c
→
=
A
−
1
b
→
{\displaystyle {\vec {c}}=A^{-1}{\vec {b}}}
A
{\displaystyle A}
{
φ
k
(
x
)
}
k
=
0
m
{\displaystyle \{\varphi _{k}(x)\}_{k=0}^{m}}
f
(
x
)
=
∑
k
=
0
m
c
k
φ
k
(
x
)
{\displaystyle f(x)=\sum _{k=0}^{m}c_{k}\varphi _{k}(x)}
[
x
1
,
x
n
]
{\displaystyle [x_{1},x_{n}]}
То есть их скалярное произведение:
⟨
φ
j
,
φ
k
⟩
=
∑
i
=
1
n
φ
j
(
x
i
)
φ
k
(
x
i
)
{\displaystyle \langle \varphi _{j},\varphi _{k}\rangle =\sum _{i=1}^{n}\varphi _{j}(x_{i})\varphi _{k}(x_{i})}
обладало бы свойством ортогональности:
⟨
φ
j
,
φ
k
⟩
=
{
≠
0
,
j
=
k
0
,
j
≠
k
{\displaystyle \langle \varphi _{j},\varphi _{k}\rangle ={\begin{cases}\neq 0,\ j=k\\\ \ 0,\ j\neq k\end{cases}}}
[
x
1
,
x
n
]
{\displaystyle [x_{1},x_{n}]}
Тогда матрица Грама станет диагональной:
A
=
(
⟨
φ
0
,
φ
0
⟩
0
⋯
0
0
⟨
φ
1
,
φ
1
⟩
⋯
0
⋮
⋮
⋱
⋮
0
0
⋯
⟨
φ
m
,
φ
m
⟩
)
{\displaystyle A={\begin{pmatrix}\langle \varphi _{0},\varphi _{0}\rangle &0&\cdots &0\\0&\langle \varphi _{1},\varphi _{1}\rangle &\cdots &0\\\vdots &\vdots &\ddots &\vdots \\0&0&\cdots &\langle \varphi _{m},\varphi _{m}\rangle \\\end{pmatrix}}}
а набор коэффициентов
c
→
=
{
c
k
}
k
=
0
m
{\displaystyle {\vec {c}}=\{c_{k}\}_{k=0}^{m}}
c
→
=
A
−
1
b
→
=
(
1
⟨
φ
0
,
φ
0
⟩
0
⋯
0
0
1
⟨
φ
1
,
φ
1
⟩
⋯
0
⋮
⋮
⋱
⋮
0
0
⋯
1
⟨
φ
m
,
φ
m
⟩
)
⋅
(
⟨
y
,
φ
0
⟩
⟨
y
,
φ
1
⟩
⋮
⟨
y
,
φ
m
⟩
)
=
(
⟨
y
,
φ
0
⟩
⟨
φ
0
,
φ
0
⟩
⟨
y
,
φ
1
⟩
⟨
φ
1
,
φ
1
⟩
⋮
⟨
y
,
φ
m
⟩
⟨
φ
m
,
φ
m
⟩
)
{\displaystyle {\vec {c}}=A^{-1}{\vec {b}}={\begin{pmatrix}{\frac {1}{\langle \varphi _{0},\varphi _{0}\rangle }}&0&\cdots &0\\0&{\frac {1}{\langle \varphi _{1},\varphi _{1}\rangle }}&\cdots &0\\\vdots &\vdots &\ddots &\vdots \\0&0&\cdots &{\frac {1}{\langle \varphi _{m},\varphi _{m}\rangle }}\\\end{pmatrix}}\cdot {\begin{pmatrix}\langle y,\varphi _{0}\rangle \\\langle y,\varphi _{1}\rangle \\\vdots \\\langle y,\varphi _{m}\rangle \\\end{pmatrix}}={\begin{pmatrix}{\frac {\langle y,\varphi _{0}\rangle }{\langle \varphi _{0},\varphi _{0}\rangle }}\\{\frac {\langle y,\varphi _{1}\rangle }{\langle \varphi _{1},\varphi _{1}\rangle }}\\\vdots \\{\frac {\langle y,\varphi _{m}\rangle }{\langle \varphi _{m},\varphi _{m}\rangle }}\\\end{pmatrix}}}
В данном случае, коэффициенты
{
c
k
}
k
=
0
m
{\displaystyle \{c_{k}\}_{k=0}^{m}}
f
(
x
)
{\displaystyle f(x)}
коэффициентами Фурье :
c
k
=
⟨
y
,
φ
k
⟩
⟨
φ
k
,
φ
k
⟩
{\displaystyle c_{k}={\frac {\langle y,\varphi _{k}\rangle }{\langle \varphi _{k},\varphi _{k}\rangle }}}
А сама приближающая функция
f
(
x
)
{\displaystyle f(x)}
обобщённым многочленом Фурье :
f
(
x
)
=
∑
k
=
0
m
⟨
y
,
φ
k
⟩
⟨
φ
k
,
φ
k
⟩
φ
k
(
x
)
{\displaystyle f(x)=\sum _{k=0}^{m}{\frac {\langle y,\varphi _{k}\rangle }{\langle \varphi _{k},\varphi _{k}\rangle }}\varphi _{k}(x)}
Однако, ортогональные функции, назовём их
{
e
k
}
k
=
0
m
{\displaystyle \{e_{k}\}_{k=0}^{m}}
{
φ
k
}
k
=
0
m
{\displaystyle \{\varphi _{k}\}_{k=0}^{m}}
⟨
φ
k
,
φ
j
⟩
{\displaystyle \langle \varphi _{k},\varphi _{j}\rangle }
Находятся
{
e
k
}
k
=
0
m
{\displaystyle \{e_{k}\}_{k=0}^{m}}
{
φ
k
}
k
=
0
m
{\displaystyle \{\varphi _{k}\}_{k=0}^{m}}
процесс Грама-Шмидта ):
e
0
=
φ
0
{\displaystyle e_{0}=\varphi _{0}}
e
1
=
φ
1
−
⟨
φ
1
,
e
0
⟩
‖
e
0
‖
2
e
0
{\displaystyle e_{1}=\varphi _{1}-{\frac {\langle \varphi _{1},e_{0}\rangle }{\|e_{0}\|^{2}}}e_{0}}
…
{\displaystyle \ldots }
e
m
=
φ
m
−
∑
k
=
0
m
−
1
⟨
φ
m
,
e
k
⟩
‖
e
k
‖
2
e
k
{\displaystyle e_{m}=\varphi _{m}-\sum _{k=0}^{m-1}{\frac {\langle \varphi _{m},e_{k}\rangle }{\|e_{k}\|^{2}}}e_{k}}
где
‖
e
k
‖
2
=
⟨
e
k
,
e
k
⟩
{\displaystyle \|e_{k}\|^{2}=\langle e_{k},e_{k}\rangle }
Таким образом мы получили приближающую функцию наилучшего среднеквадратичного приближения, в виде разложения в ряд Фурье(обобщённого многочлена):
f
(
x
)
=
∑
k
=
0
m
c
k
e
k
=
∑
k
=
0
m
⟨
y
,
e
k
⟩
‖
e
k
‖
2
e
k
{\displaystyle f(x)=\sum _{k=0}^{m}c_{k}e_{k}=\sum _{k=0}^{m}{\frac {\langle y,e_{k}\rangle }{\|e_{k}\|^{2}}}e_{k}}
где
c
k
=
⟨
y
,
e
k
⟩
⟨
e
k
,
e
k
⟩
=
⟨
y
,
e
k
⟩
‖
e
k
‖
2
{\displaystyle c_{k}={\frac {\langle y,e_{k}\rangle }{\langle e_{k},e_{k}\rangle }}={\frac {\langle y,e_{k}\rangle }{\|e_{k}\|^{2}}}}
Однако, такой метод нахождение базисных функции
{
e
k
}
k
=
0
m
{\displaystyle \{e_{k}\}_{k=0}^{m}}
Для того чтобы избежать накопления ошибки при вычислениях базисных функций
{
e
k
}
k
=
0
m
{\displaystyle \{e_{k}\}_{k=0}^{m}}
рекуррентным соотношением ортогональных многочленов :
e
k
+
1
=
(
φ
1
−
β
k
)
e
k
−
α
k
e
k
−
1
,
{\displaystyle {e_{k+1}\ =\ (\varphi _{1}-\beta _{k})\ e_{k}\ -\ \alpha _{k}\ e_{k-1}},}
где
β
n
=
⟨
φ
1
e
k
,
e
k
⟩
⟨
e
k
,
e
k
⟩
,
α
k
=
⟨
φ
1
e
k
,
e
k
−
1
⟩
⟨
e
k
−
1
,
e
k
−
1
⟩
{\displaystyle \beta _{n}={\frac {\langle \varphi _{1}e_{k},e_{k}\rangle }{\langle e_{k},e_{k}\rangle }},\qquad \alpha _{k}={\frac {\langle \varphi _{1}e_{k},e_{k-1}\rangle }{\langle e_{k-1},e_{k-1}\rangle }}}
Для случая когда приближение производится степенными функциями, т.е.
{
φ
k
}
k
=
0
m
=
{
x
k
}
k
=
0
m
{\displaystyle \{\varphi _{k}\}_{k=0}^{m}=\{x^{k}\}_{k=0}^{m}}
e
k
+
1
=
x
e
k
−
⟨
x
e
k
,
e
k
⟩
⟨
e
k
,
e
k
⟩
e
k
−
⟨
x
e
k
,
e
k
−
1
⟩
⟨
e
k
−
1
,
e
k
−
1
⟩
e
k
−
1
{\displaystyle e_{k+1}=xe_{k}-{\frac {\langle xe_{k},e_{k}\rangle }{\langle e_{k},e_{k}\rangle }}e_{k}-{\frac {\langle xe_{k},e_{k-1}\rangle }{\langle e_{k-1},e_{k-1}\rangle }}e_{k-1}}
где
k
=
1
,
2
,
.
.
;
e
0
=
1
,
e
1
=
x
−
⟨
x
,
e
0
⟩
⟨
e
0
,
e
0
⟩
e
0
{\displaystyle k=1,2,..;\ \ \ \ e_{0}=1,\ \ \ \ e_{1}=x-{\frac {\langle x,e_{0}\rangle }{\langle e_{0},e_{0}\rangle }}e_{0}}
Иногда приведённые выше многочлены носят названия многочленов Чебышева , но не стоит их путать с классическими многочленами Чебышева .
Рекуррентное соотношение может быть упрощено[1]
y
{\displaystyle y}
[
x
1
,
x
n
]
{\displaystyle [x_{1},x_{n}]}
[
−
1
,
1
]
{\displaystyle [-1, 1]}
t
:
[
x
1
,
x
n
]
→
[
−
1
,
1
]
{\displaystyle t:[x_{1},x_{n}]\rightarrow [-1,1]}
Примером отображения
t
{\displaystyle t}
t
(
x
)
=
2
x
−
(
x
n
+
x
1
)
x
n
−
x
1
{\displaystyle t(x)={\frac {2x-(x_{n}+x_{1})}{x_{n}-x_{1}}}}
Тогда рекуррентное соотношение будет иметь более простой вид [1]
e
k
+
1
(
t
)
=
t
e
k
(
t
)
−
α
k
e
k
−
1
(
t
)
{\displaystyle e_{k+1}(t)\ =\ t\ e_{k}(t)\ -\ \alpha _{k}\ e_{k-1}(t)}
где
e
0
=
1
;
e
1
=
t
;
α
k
=
⟨
t
e
k
,
e
k
−
1
⟩
⟨
e
k
−
1
,
e
k
−
1
⟩
;
{\displaystyle e_{0}=1;\ \ \ \ e_{1}=t;\ \ \ \ \ \alpha _{k}={\frac {\langle te_{k},e_{k-1}\rangle }{\langle e_{k-1},e_{k-1}\rangle }};}
Ссылки [ ]
↑ 1,0 1,1 "Вывод рекуррентного соотношения ортогональных многочленов из процесса ортогонализации Грама-Шмидта, а также схема применения полученного рекуррентного соотношения" Сухопаров C.Ю. http://vixra.org/pdf/1411.0072v1.pdf Используемые материалы [ ] 1. "Вывод рекуррентного соотношения ортогональных многочленов из процесса ортогонализации Грама-Шмидта, а также схема применения полученного рекуррентного соотношения" Сухопаров С.Ю.[1]
2. http://solidbase.karelia.ru/edu/meth_calc/files/09.shtm «Аппроксимация функций методом наименьших квадратов»





![{\displaystyle D[{\boldsymbol {\varepsilon }}]={\frac {1}{n}}\sum _{i=1}^{n}(y_{i}-f({\vec {x}}_{i},{\vec {c}}))^{2}}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/1160de5da2daccfdb6c01b42114136c46f21e324)



![{\displaystyle D[{\boldsymbol {\varepsilon }}]={\frac {1}{n}}\sum _{i=1}^{n}(y_{i}-f(x_{i},{\vec {c}}))^{2}}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/739ac22ef31f90a88a4fa7ea22325d34c3c7d7ea)
![{\displaystyle D[{\boldsymbol {\varepsilon }}]}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/213c3993a18e749f3605938fbeaefa7adf555515)
![{\displaystyle {\frac {\partial D[{\boldsymbol {\varepsilon }}]}{\partial {\vec {c}}}}=0}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/ef9eb1e846a372380e2aaa729cb8823fe0f55995)
![{\displaystyle {\frac {\partial D[{\boldsymbol {\varepsilon }}]}{\partial {\vec {c}}}}={\frac {\partial D[{\boldsymbol {\varepsilon }}]}{\partial c_{0}}}{\vec {e}}_{0}+\ldots +{\frac {\partial D[{\boldsymbol {\varepsilon }}]}{\partial c_{m}}}{\vec {e}}_{m}=0}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/c8e7c2043f6e2f173e27349b519609e405ede6ea)





![{\displaystyle D[{\boldsymbol {\varepsilon }}]={\frac {1}{n}}\sum _{i=1}^{n}(y_{i}-\sum _{k=0}^{m}c_{k}\varphi _{k}(x_{i}))^{2}}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/8b1a0891080ba3a5a99bef011eaddbfe20314b28)
![{\displaystyle D[{\boldsymbol {\varepsilon }}]\equiv D}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/5431827022d204208a7f32171cceda9e395eaf93)












![{\displaystyle \sum _{i=1}^{n}[y_{i}-\sum _{k=0}^{m}c_{k}\varphi _{k}(x_{i})]\varphi _{j}(x_{i})=0}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/c4573029b079295f77b542a86a46869bb57b4386)


![{\displaystyle {\begin{cases}\sum _{i=1}^{n}[y_{i}-\sum _{k=0}^{m}c_{k}\varphi _{k}(x_{i})]\varphi _{0}(x_{i})=0\\\sum _{i=1}^{n}[y_{i}-\sum _{k=0}^{m}c_{k}\varphi _{k}(x_{i})]\varphi _{1}(x_{i})=0\\\dots \\\sum _{i=1}^{n}[y_{i}-\sum _{k=0}^{m}c_{k}\varphi _{k}(x_{i})]\varphi _{m}(x_{i})=0\\\end{cases}}}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/59a1da2bb8768eda0dc8f609ce10e3b7f47f61d7)



![{\displaystyle {\begin{cases}\sum _{i=1}^{n}[c_{0}\varphi _{0}^{2}(x_{i})+c_{1}\varphi _{0}(x_{i})\varphi _{1}(x_{i})+...+c_{m}\varphi _{0}(x_{i})\varphi _{m}(x_{i})]=\sum _{i=1}^{n}y_{i}\varphi _{0}(x_{i})\\\sum _{i=1}^{n}[c_{0}\varphi _{1}(x_{i})\varphi _{0}(x_{i})+c_{1}\varphi _{1}^{2}(x_{i})+...+c_{m}\varphi _{1}(x_{i})\varphi _{m}(x_{i})]=\sum _{i=1}^{n}y_{i}\varphi _{1}(x_{i})\\\dots \\\sum _{i=1}^{n}[c_{0}\varphi _{m}(x_{i})\varphi _{0}(x_{i})+c_{1}\varphi _{m}(x_{i})\varphi _{1}(x_{i})+...+c_{m}\varphi _{m}^{2}(x_{i})]=\sum _{i=1}^{n}y_{i}\varphi _{m}(x_{i})\\\end{cases}}}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/75d0222d186eeccd57bcb3f344b47d76207d798e)





































![{\displaystyle [x_{1},x_{n}]}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/a9ee63ba414bfbe0f89fb3bf0031e0ceb805f9b2)






















![{\displaystyle [-1,1]}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/9f5f18fffd3b74164d78923ff5e7c0b8f8fad379)
![{\displaystyle t:[x_{1},x_{n}]\rightarrow [-1,1]}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/deee97d22ee086792b7c159485dfa1328cd662d8)




{kind=link}